Plugin users: There is a picture in the problem statement.
A coding tree is a proper binary tree (in which every node has either zero or two children) where each leaf has a distinct character assigned to it. This allows us to encode a string made up of the characters in the leaves as follows: For every character in the string, find the path from the root of the coding tree to the matching leaf. If following the left child of a node, append a 0 to the encoding, otherwise a 1. For instance, the string "helloworld" would, using the tree below, be encoded as "011001111111100001000111010" (zeros are the left branches). To decode a string of 0's and 1's, one just reverses this procedure: start at the root of the tree and follow the edges downwards: 0 for left, 1 for right. When a leaf is reached, append the leaf's character to the output string, and continue from the root.
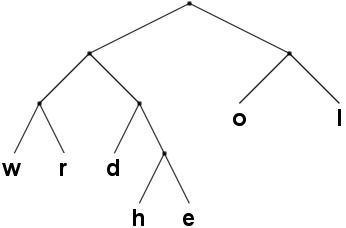
One way (albeit not a very good one) to represent the coding tree is to describe for each character the path to the leaf. For instance, the tree in the picture above would be described as
{"h 0110",
"e 0111",
"l 11",
"o 10",
"w 000",
"r 001",
"d 010"}
In this problem, however, some characters in the binary codes in this representation have been damaged (and replaced by a question mark, '?'). Given a damaged representation
and an encoded message, determine if it's possible to uniquely decode the encoded message,
using the properties above about a well formed coding tree (see example 0).
You may also use the fact that the encoded message must be fully decodable
(see example 3). You are guaranteed that there will be at least one
way to decode the message.
Create a class DamagedTree containing the method decode which takes a String[], tree, representing a damaged representation of a coding tree in the format above, and a String[], encodedMessage, the encoded message (concatenate the elements in encodedMessage to get the full encoded message). If there is a way to uniquely decode this message, return this decoded message. Otherwise return the empty string (see example 1).
|