For computers it can be hard to determine in which language a given text is written. A simple way to try to determine the language is the following: for the given text and for some sample texts, for which we know the languages, we determine the letter frequencies and compare these.
The frequency of a letter is the total number of occurrences of that letter divided by the total number of letters in the text. To determine this, we ignore case and non-letter characters.
Once the letter frequencies of the text and of a language are known, we can calculate the difference between the two. This difference we define by the sum of the squared differences of the frequencies:
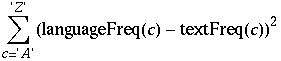
The lesser this value, the closer text resembles that language. Compare text with each element of languages and return the (0-based) index of the language that has the smallest difference with text. In case of a tie, return the smallest index.
|